Hello all, long time no see! In this article I’ll be showing some weirdness I found while parsing LSASS minidumps (as one does) in the last few days. Special thanks to Microsoft pushing an update for windows server 2012 which caused a few hours of extra work for me and allowing me to notice this quirk.
Foreword: the observations made in this article were not caused by the update, it was always like this. Also, this is not a vulnerability according to me (and definitely not according to MS for sure) regardless I found it funny enough to write this article.
TL;DR LSASS encrypts user credentials using AES-CFB which means that most of the secret values can be decrypted using an incorrect IV. Correct key is needed, but it is relatively easy to identify in the process’ memory using crude parsers, because they are stored in well-known structures.
Soo.. where were we? Last few days were a bit exhausting with daily work and on top of that I got a new issue on pypykatz’s github page in which the awesome @forensenellanebbia notified me -again- that my code breaks while parsing specific LSASS dump files. Shout out to him because he is always really helpful in providing full stack traces and testcases and in this case even hunting down the offending updates!! (FOSS dev’s dream come true)
Specifics: Windows 2012 Server with updates KB5003696 and KB5003697 were introducing some breaking changes in pypykatz (and mimikatz) because they modified the layout of the structures which hold the cached credentials. To be more precise, the MSV package’s -where NT/LM/SHA1 hashes of the user’s password are stored- PKIWI_MSV1_0_LIST structure’s start signature and pointer offset were now different compared to the pre-update ones. (ovbiously that’s not how MS calls that struct, but Benjamin Delpy does and that’s good enough for me)
What does that mean? you might ask.
For mimikatz it means when trying to parse a minidump file taken from this updated server you’ll be greeted with “ERROR kuhl_m_sekurlsa_acquireLSA ; Logon list” error.
For pypykatz it means you’ll get a long stack-trace with the exception message “All detection methods failed”.
But why can’t pypykatz show a nice and simple error message instead of printing out long stack traces? you might ask. Well, now that you mention it… where did you get that minidump file from exactly? See… it’s better not be asking silly questions…
Now that we both agree that seeing an error message instead of getting high on the dopamine rush our brains release when seeing the domain admin’s NT hash or… wait is that WDIGEST? nevermind all this! gimme gimme gimme
Solution to the parsing errors: finding the correct signatures/offsets/structures but how? A normal human might load the minidump file in windbg and wait for the symbols to load, giving you an “easy” access to the information you need.
Where is the fun in that? Let’s do it in a hex editor!
Several hours later I figured out the correct signature and offsets for the AES and TDES keys which protect all(most all) credentials in LSASS. That was relatively easy because the structs holding these keys are fairly recognizable in an editor, but there is no struct for the IV as it’s just a pointer to a memory address and indistinguishable from any other random bytes (okay maybe I could’ve done some entropy calc, but I just checked a few possible locations manually and picked one that looked fairly random). So I picked one and guessed that if everything goes correctly in the decryption process then the IV is good, if I see garbage then obviously I need to keep on looking for the correct offset for the IV. However that’s not what happened!
The parsing finished without errors, that doesn’t mean it was competently successful because pypykatz has a lot of fail-safes built in so you can squeeze out creds from corrupted dumps as well. I was suprized to see this actual result from one the dumpfiles @forensenellanebbia sent to me:
== WDIGEST [133def]==
username Administrator
domainname WIN-QSQO10V59K4
password 꾭痰摻w0rd!
password (hex)adaff0757b64810077003000720064002100000000000000
If you squint hard enough you can guess the password. But how? First I guessed one (of the many!) structures might have changed as well but after wasting some time double-checking the pointers/addresses/values they seemed fine. Also the password’s bytes shown above is what the AES decryption function yields. WTF???? did we break AES???
Ofc not, I wouldn’t be writing Medium articles if I had the mathematical prowess doing that.
It’d be a good time to sit down, relax and learn how the secrets are protected in LSASS.
Just joking, that would be an entire book, so instead here is the really really really watered down version.
Getting everything needed to decrypt the credentials in LSASS is like a fetch quest in your least-favorite RPG, where you need to obtain 2 encryption keys, one for AES and one for TDES, also you’ll need an IV which is the same for both of them. That is the bare minimum so you’ll be able to decrypt stuff. Then you’d need to identify what exactly you want to decrypt for that you’ll need to find the start addresses of linked lists/AVL trees -depending on the module you are interested in- which will point to structures which will point to linked lists which will point to structures… you get the gist. At the end of the rainbow you’ll find a blob of data in memory which is encrypted by either the TDES or AES ciphers. How would you know which one to use to decrypt? Well, I haven’t the slightest clue but it seems it’s based on the length of the encrypted data. Also I told you to stop asking questions!
Mimikatz (and pypykatz) uses an advanced ML/AI/blockchain based crypto detection method where they check if the length of the encrypted data is divisible by 8 then it’s TDES otherwise it’s AES. The really important part for this article is the mode of operation for the ciphers which are the following:
TDES-CBC and AES-CFB. Crypto savvy readers might see where this is going… The half-correct results were all encrypted using AES-CFB.
That’s all you’d need to know for now about decrypting credentials in LSASS. The next step in understanding why we could see half of the plaintext password is to observe how AES-CFB behaves under normal conditions. Let’s take the following example:
This code takes a string of value “secret” and encrypts it using AES-CFB, then creates a new cipher with the same key and IV and decrypts the encrypted secret. No one gets surprised that at the end of the decryption process we get the original secret message back.
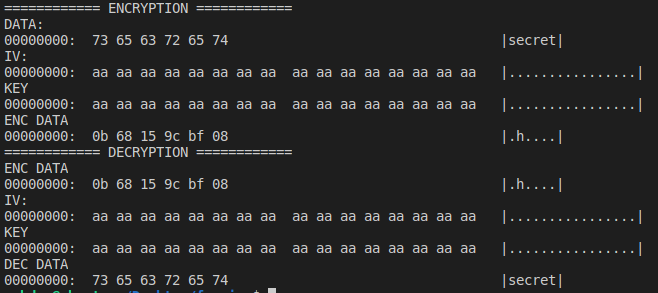
Now! Let’s change the code a bit, and use a different IV for encryption and decryption. We expect that the resulting data will be a garbled mess and will not show the original data of “secret”.
Executing the code above we get the following
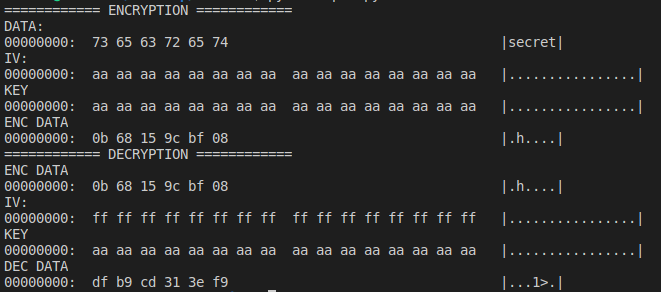
Again, not surprising at the end of the decryption process we get some unrecognizable data which is definitely not our secret string.
But in real-world we are not trying to encrypt 7 characters, rather a few hundred chars maybe? Let’s see what the output is of our faulty decryption algo with the incorrect IV, but let’s supply a larger data to be decrypted!
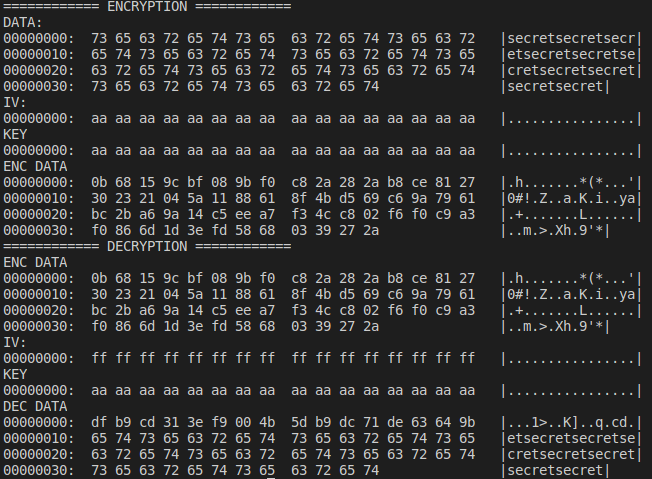
Omg! What happened?! After the decryption algorithm finished we got back the original plaintext after 16 bytes! *shocked Pikatchu face*
But how does that translate to our current problem with LSASS? Surely the first 16 incorrect bytes would destroy crucial pointers which would make the decryption impossible!
No.
Here is a structure which holds credentials but has been decrypted with an “incorrect” IV.
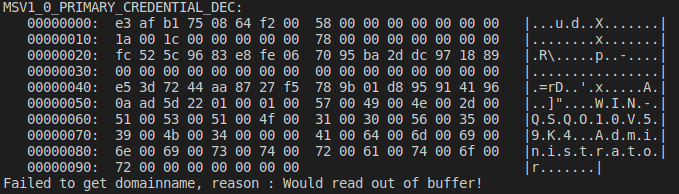
And here is the very same structure decrypted with the correct IV
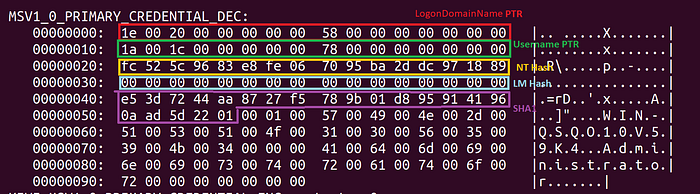
As you can see in this (correctly) decrypted MSV1_0_PRIMARY_CREDENTIAL struct, destroying the first 8 bytes will only garble half of the LSA_UNICODE_STRING -incorrectly referred to as PTR on the picture, sorry- structure which holds the logon domain name. Please note that the pointers inside this structure are relative to the beginning of this same blob opposed to the VAD of the LSASS process (logical, but I thought I’ll point it out). The point here is that you can easily recover the garbled information if you know the structure which you just decrypted.
And now! The thrilling conclusion!
I have shown that you can reliably obtain user credentials (at least NT hashes) without knowing the IV for the decryption algorithm because MS decided to use AES-CFB cipher to protect the secrets. Why they did that, I have no clue.
This fact will certainly not change the way of how mimikatz or pypykatz operates, but you may skip a step if you intend to write your crude parser.
PS: pypykatz has the correct parser for the “new” updated Windows Server 2012’s LSASS.
